







About the
Adapt Project


Pre-assessment: to measure the starting level of knowledge
In-course assessments: to improve the assimilability of the material
Post-course assessment: to
measure the level
of knowledge quality
We used Big Data methods to enable the system to handle high workloads. In particular, we chose MongoDB as a reliable database, providing easy replication and horizontal scaling capabilities. This helps deal with intense write loads easily and ensures the stable functioning of the high-load system. For example, the current course on Lagunita (the Stanford University Online learning platform) involves 10,000 students with individual learning paths.

We created a generic solution (so-called recommendation engine, namely the Adapt), able to work with any LMS through API to provide adaptive assessment experience.
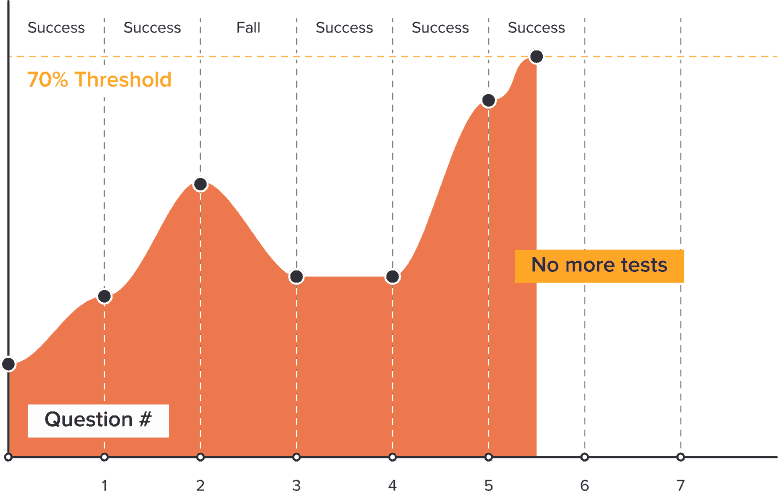
Adapt knows the answers on a pool of tests divided by some skills set
– Based on test success/failure, Adapt calculates the probability of the student mastering the corresponding skill.
As an example: success on tests 1 & 2 increases the probability that student mastered the skill; failure with test 3 makes the statistics worse
– Adapt keeps giving tests from some particular skill set till the probability of subject mastery reaches some level. This level is titled “threshold”
– When the “threshold” inside particular skill set is reached, Adapt blocks related tests. Hence, if the student is smart he can be given about 3-4 tests for each skill set instead of 10-15 to prove that he mastered the subject

Here is how Adapt works in Stanford’s online learning platform Lagunita

